A humanoid in the wild
OpenHLM is a recipe for whole-body humanoid loco-manipulation: it maps a language instruction and the robot's observation images into coordinated motion across every one of the robot's degrees of freedom.
So what can it do? Mix in just 20 outdoor demos with our lab data, and the humanoid moonlights as the campus janitor—fully autonomous, outdoors, no mocap. As far as we know, no humanoid has done this in the wild before.
Comparison with SOTA
How does OpenHLM stack up against other humanoid VLAs? We compare at the system level with two representative baselines: GR00T N1.6 and Ψ₀.
The evaluation is a challenging long-horizon task: the robot walks between a low table, a medium table, and a tall shelf, picking two language-specified fruits—one per hand—and placing them into separate containers. This spans the humanoid's full vertical workspace and requires language grounding across 20 ordered fruit pairs. OpenHLM reaches 87.5% task progress using less than half the demonstration time of either baseline.
OpenHLM (HuMI Co-Training)
GR00T N1.6
Ψ₀
HLM Tasks
Want more tasks? We introduce 12 language-conditioned tasks that target different aspects of whole-body loco-manipulation behavior, organized into four categories: (1) pick-and-place with locomotion, (2) whole-body workspace extension, (3) using body parts as manipulators, and (4) loco-manipulation under environmental constraints. OpenHLM achieves strong performance across all 12 tasks, with average task progress exceeding 90%.
Cola Placement
01 / 12
Shelf Cup Transfer
02 / 12
Bottle Disposal
03 / 12
Jar Opening
04 / 12
Toy Stowing
05 / 12
Sword Extraction
06 / 12
Cart Pushing
07 / 12
Shuttlecock Setup
08 / 12
Pig Placement
09 / 12
Gum Can Placement
10 / 12
Shelf Cube Transfer
11 / 12
Pouring
12 / 12
How did we get here?
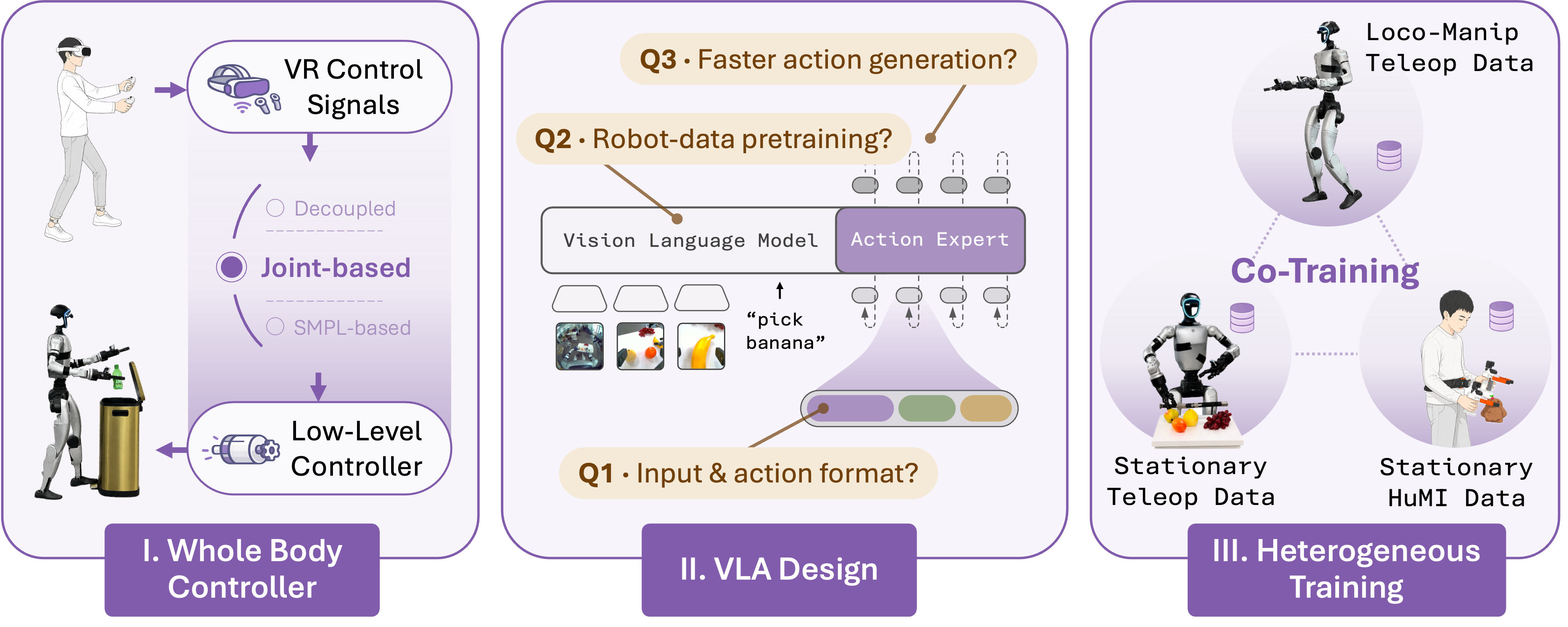
None of this comes from a single trick. We construct OpenHLM through controlled experiments, one design decision at a time, in three phases that build up to a concrete recipe for whole-body humanoid loco-manipulation.
Low-level controller and teleoperation: how to design the controller and its teleop interface for high-quality whole-body demonstrations. Whole-body VLA policy design: which adaptations turn a VLA built for static and wheeled robots into a whole-body humanoid policy. Heterogeneous co-training: whether cheaper data sources can extend the policy beyond what whole-body teleop alone covers.
Low-level controller and teleoperation
We follow a two-level hierarchical control framework: a high-level policy (the operator during data collection, the learned VLA at deployment) emits reference whole-body commands, and a lightweight low-level controller tracks them. With this framework fixed, the interface between the two determines both what the operator can express and what action space the VLA learns.
We compare three teleoperation methods representative of recent humanoid systems: decoupled control (dual-arm IK plus an RL lower-body controller tracking a base-velocity and root-height command, 21-D), VR 3-point (head and wrist poses plus a navigation command, 24-D), and joint-based whole-body teleoperation (a portable motion-capture rig retargeted in real time to every humanoid joint, 32-D). We collect matched demonstrations under each interface and train one VLA per method.
Teleop Method Comparison
Select a task to compare task progress, rollout time, and footsteps. N/A marks tasks the interface cannot express by construction.
Decoupled Control
VR 3-Point
Joint-Based Whole-Body
The numbers tell a clear story. Joint-based whole-body teleoperation is the only interface that completes all three tasks. The two alternatives expose only a subset of the humanoid's degrees of freedom, so tasks like a foot depressing a pedal or the whole body squatting under a shelf are unreachable by construction. Based on these results, we adopt joint-based whole-body teleoperation as the data-collection interface that all later phases build on.
Whole-body VLA policy design
Existing VLAs bring vision-language reasoning and manipulation priors, but nearly all target static or wheeled dual-arm platforms—none were designed for humanoid loco-manipulation. So how do we adapt one into a whole-body humanoid policy, and which design choices actually matter? We organize the exploration into three families: the action and proprioception interface, the role of pretraining, and faster action generation—ablating one component at a time on a 4-task subset.
Adapting π₀.₅'s action space to the humanoid involves four choices: projection initialization, action ordering, absolute vs. relative targets, and proprioceptive input. Flipping any one produces only a slight drop—no single choice is the bottleneck.
Initialized from π₀.₅ (pretrained on dual-arm robots), the policy reaches 91% task progress; PaliGemma (same architecture, vision-language only) drops to 60%; random init collapses to 42%. The cross-embodiment gap is real, but dwarfed by the gap between any robot pretraining and none.
Counterintuitively, both one-step alternatives reach lower validation action MSE than π₀.₅'s 10-step flow matching—yet on the robot they underperform it by ~20 task-progress points. So we keep multi-step inference.
Heterogeneous co-training
With the whole-body VLA established, scaling to every task through loco-manipulation teleop is expensive. We turn to two cheaper data sources and ask whether co-training can incorporate them effectively: stationary teleoperation (the same humanoid with feet planted, manipulation only) and HuMI (robot-free demonstrations captured with low-cost wearable devices). The question is whether either can extend the policy to held-out tasks that whole-body teleop never covers.

Whole-Body Teleop
21 min / held-out taskFull loco-manipulation teleop on the humanoid; the expensive oracle data source.

Stationary Teleop
13 min / held-out taskThe same humanoid with feet planted: manipulation only, no locomotion—cheaper to collect.

HuMI
7 min / held-out taskA robot-free rig of hand-held UMI grippers and body-pose trackers; the humanoid stays out of the loop.
on Held-Out Tasks 9–11
With the policy trained on whole-body teleop for Tasks 1–8, we co-train it with cheaper data on three held-out tasks (9–11) that whole-body teleop never covers. Both streams lift average progress on these tasks from 36% to near the oracle—with no extra whole-body teleop.